- As a
- software developer using GitHub code scanning
- I want to
- get quick feedback about security vulnerabilities on my PRs
- But
- the current code scanning analyses often take too long to deliver updated feedback after a code change.
- Incremental CodeQL helps by
- delivering an update time that is proportional to the size of a code change
- Unlike
- the current code scanning analyses which re-analyze the entire code base from scratch irrespective of the change size.
Motivating example
GitHub code scanning is powered by the CodeQL analysis engine. The strength of code scanning lies in the sophisticated open source CodeQL analyses that engineers at GitHub and experts from the security community write to find security vulnerabilities. CodeQL offers unmatched support for deep and precise static analysis for a number of popular programming languages.
Consider a concrete PR in the mosquitto-go-auth repository where code scanning provided automated feedback as a bot reviewer:
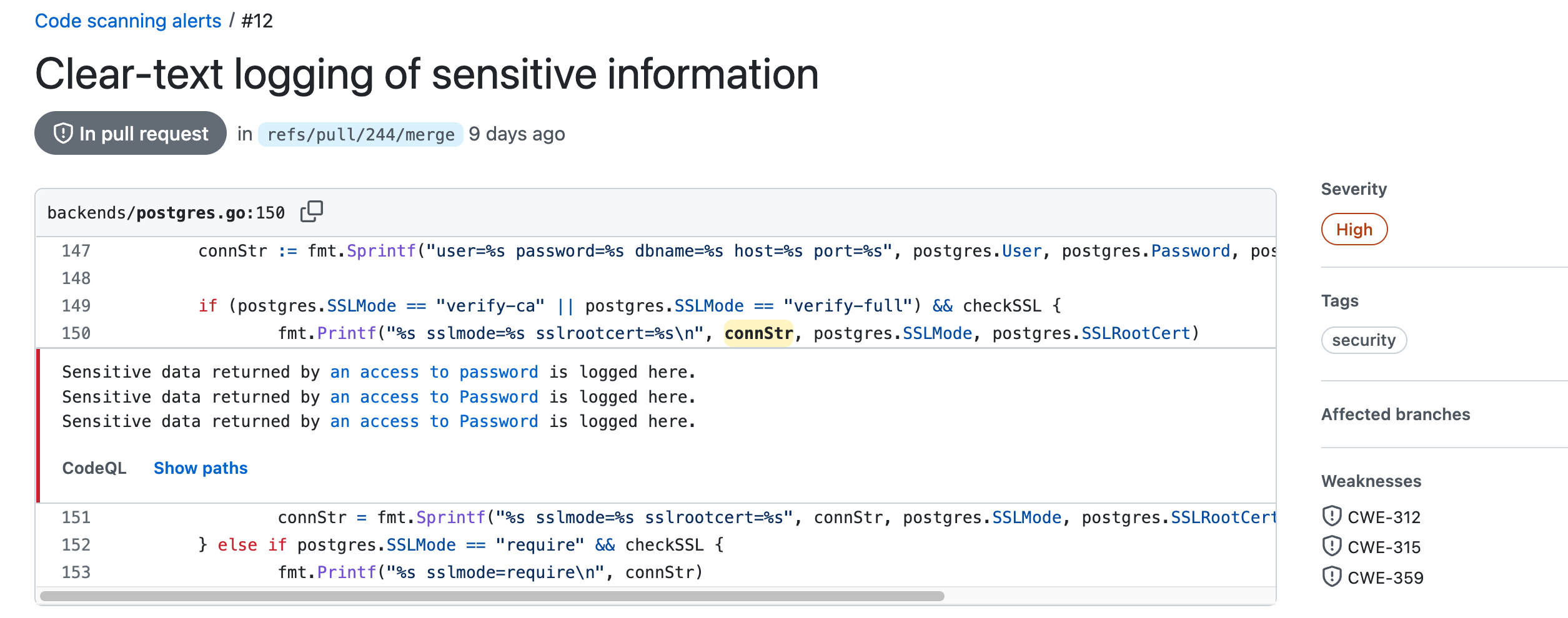
The security vulnerability was found by a CodeQL analysis that automatically runs after a push to the PR. This is a severe issue and even the corresponding CWE numbers are displayed.
While this kind of automated feedback is important to prevent accidentally introducing security vulnerabilities, it is only really helpful if it comes in a timely manner. Analysis results should ideally be available within (at most) a minute or two after a code change, otherwise developers may switch context and start working on something else, which quickly decreases the usefulness of the automated analysis.
If we investigate the logs, we can see that the analysis took around 6 minutes on the code base:
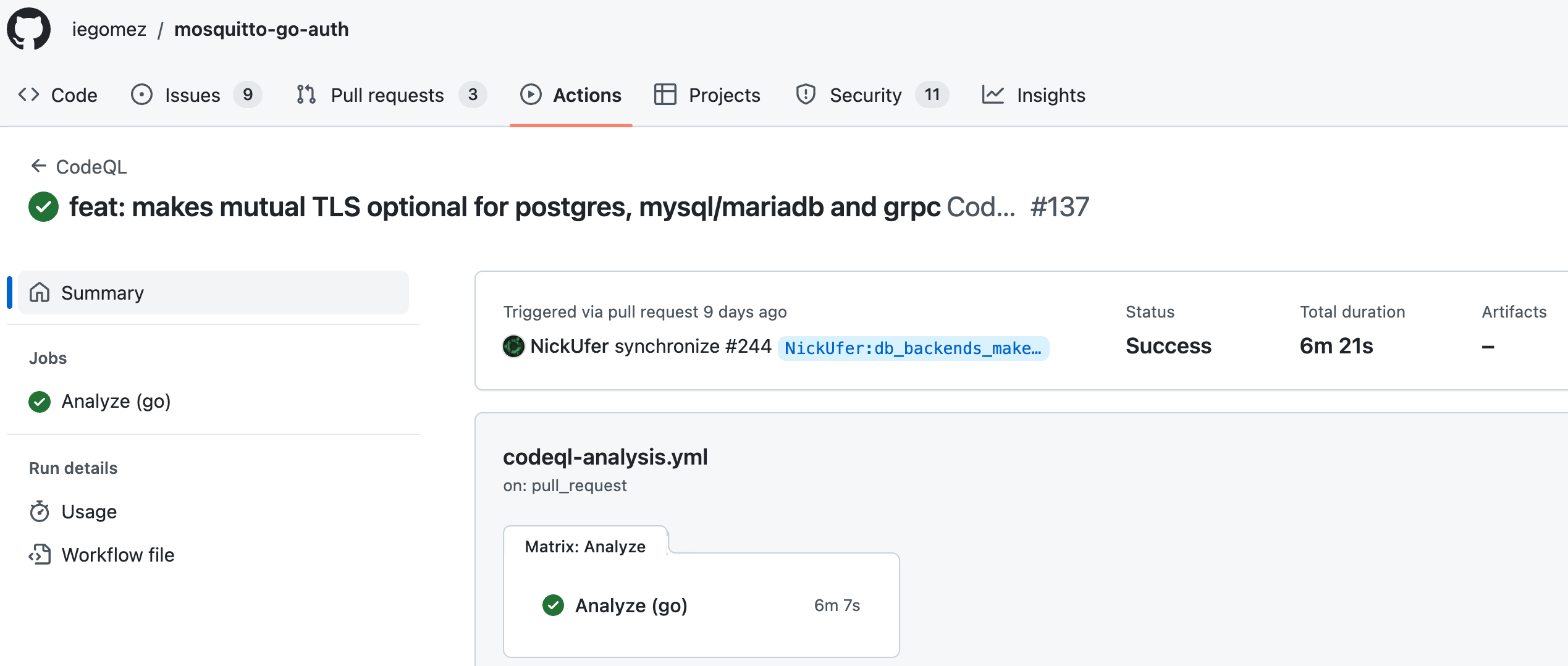
Unfortunately, this run time cost must be paid every time the analysis runs, even if only a very small part of the code base changes. As an extreme example, even if the developer just fixes a typo in a comment they still have to wait 6 minutes before updated (and unchanged!) analysis results become available. This is because all analysis runs are entirely independent from each other, and previous results are not reused in any way.
In the Incremental CodeQL project, we investigate whether we can speed up CodeQL analyses with incrementalization. Instead of repeated re-analysis from scratch on the entire code base, an incremental analysis keeps around the previously computed result and updates that based on the changed code parts. Prior research shows that this approach can lead to significant performance improvements because a small program change typically leads to small changes in the analysis result. In turn, developers can expect to see much quicker feedback on their PRs (seconds instead of minutes) because the runtime becomes proportional to the size of the code change and not the size of the entire code base.
Project phases
Phase 1: Is it even possible to incrementalize CodeQL analyses?
While the idea of incrementalization is promising when it comes to static analyses, sophisticated static analyses are not necessarily compatible with incrementalization simply because of their nature. For example, analyzing across functions is typically required for good precision, but such analyses come with a high computational cost. When considering the transitive effects of called functions, it is easy to introduce program changes that have a large impact on previously computed results, making it difficult to gain anything with incremental behavior. To this end, we first investigate if it is really the case that typical program changes have a small impact on already computed results. We take real-world projects with their commit histories together with sophisticated CodeQL analyses and we look for empirical evidence that incrementality can actually be efficient.
We already carried out concrete experiments as part of this phase. We took a concrete CodeQL analysis for Ruby which identifies potential SQL injections in Ruby source code. The analysis is representative in terms of its complexity and practical relevance because it exhibits features and building blocks that industry-strength static analyses typically employ: inter-procedural reasoning with flow-sensitivity based on SSA representation of the input program. We measured the impact of program changes using a technique introduced in prior research in the context of incremental static analyses. Concretely, we took real-world Ruby projects with their commit histories. For each commit, we considered the analysis result that got computed for the immediately preceding commit, and we measured how much of the previous result needs to be changed to get to the result representative for the new commit. Below we present a plot for one of the Ruby projects we benchmarked:
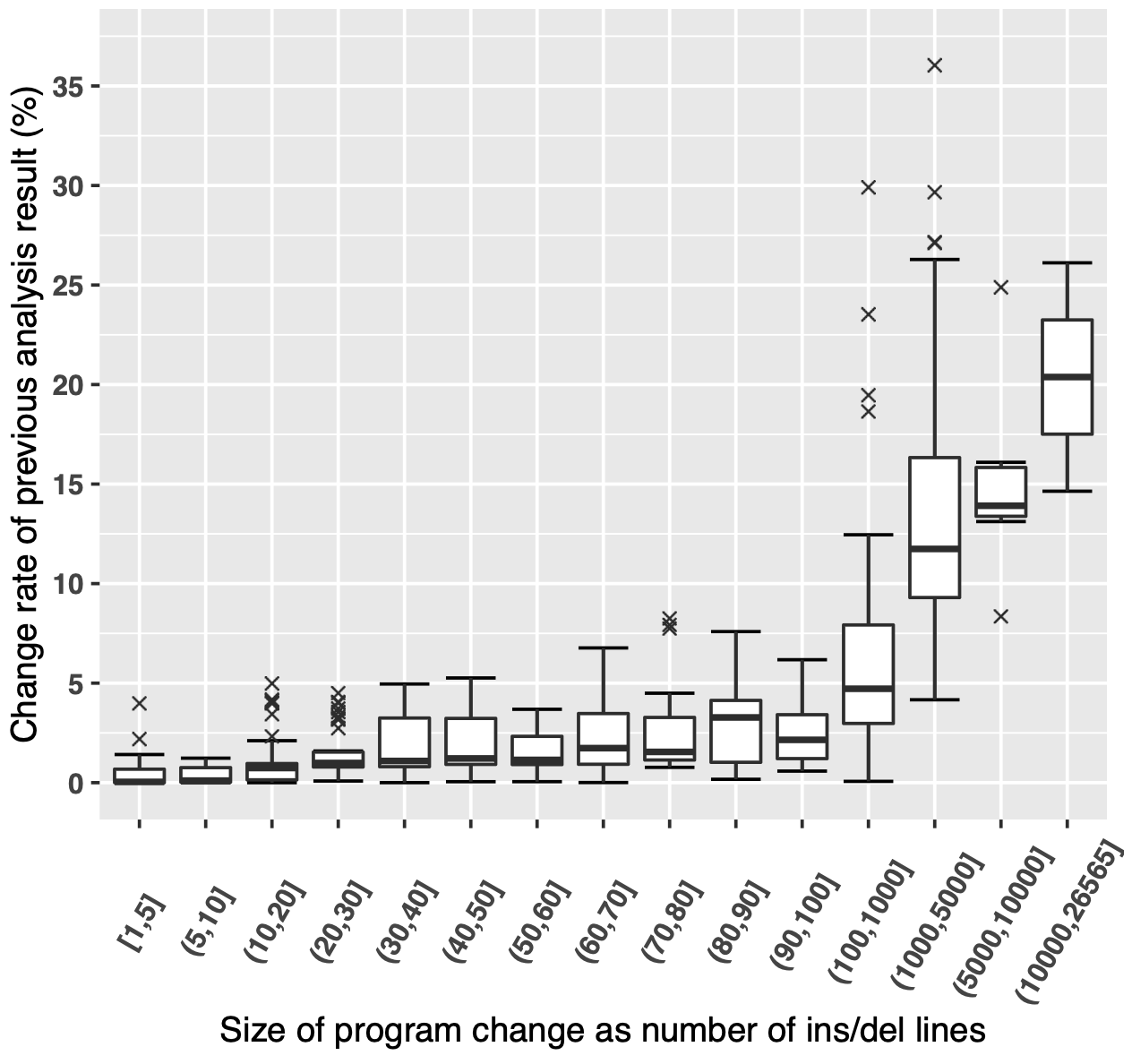
The x axis shows the size of the commits arranged into buckets. The number range shows how many lines were inserted/deleted by a particular commit. The y axis shows the change rate of the previous analysis result, that is how much of the previous result needs to be changed to get to the new result. The plot shows the trend that small commits lead to small changes in the analysis result, and we only see >10 % change rates for considerably large commits (affecting more than a 1000 lines). We observed a similar trend for other Ruby projects, as well. All in all, these results show that incrementalization has potential when it comes to speeding up typical CodeQL analyses.
Phase 2: Can we create a prototype evaluator that exploits the incrementalizability of CodeQL analyses?
The goal of this phase is to show that we can actually exploit the fact that typical program changes have a small impact on previously computed analysis results. To investigate this, we create a prototype incremental evaluator for CodeQL. Instead of changing the production CodeQL evaluator (which is a complex, heavily optimized piece of software), we take an existing incremental evaluator called Viatra Queries (VQ) and use that to execute CodeQL analyses. We chose VQ because it has been reported to deliver good incremental performance for inter-procedural Datalog-based static analyses and because it has good expressive power in terms of the kinds of analyses it supports. Still, when it comes to QL, the expressive power of VQ is not enough, so a challenge in our work is figuring out how to bridge the gap between the two systems when transforming QL analyses to the format that VQ understands.
With this work, we are focused on relative performance improvements and not so much on the absolute numbers: We want to see that an incremental update, on average, takes only a small fraction of a complete re-analysis. We do not plan to replace the production CodeQL evaluator at this phase of the project, this is why the absolute performance is not that important. For benchmarking of run times, we use the same real-world projects and their commit histories that we used in the previous phase. Primarily we benchmark run times, but we pay careful attention to correctness, as well: We automatically verify that the results computed by the other solver are exactly the same as what CodeQL would compute if we would run it from scratch.
We can already report on concrete results as part of this phase:
- We see great incremental performance. There is a linear correlation between the update time and the size of the commit. In terms of absolute numbers, we see update times on the order of a few seconds on average and less than 15 seconds even for the biggest commits.
- The price of the fast update times is the high initialization time (run time of the first from-scratch analysis) and memory use. Even for smaller projects (less than 10 KLoC in size), we see that the initialization can take an hour, while the memory use can reach several tens of GB.
In sum, our experiment is successful in showing the speed-ups we can gain with incrementalization, but it also shows that evaluating CodeQL queries with our prototype is not the full solution yet.
Phase 3: Can we make the production CodeQL evaluator incremental?
While the incremental update times we measured suggest that it is worth investigating incrementalization of production CodeQL, the high memory use is a significant concern. We do have some concrete ideas on how we could mitigate the problem, but further work is required before incrementalization can make its way to production for real. At this point, we have no concrete timeline for this work. Meanwhile, the CodeQL team is working hard on other approaches to improve performance, as well.